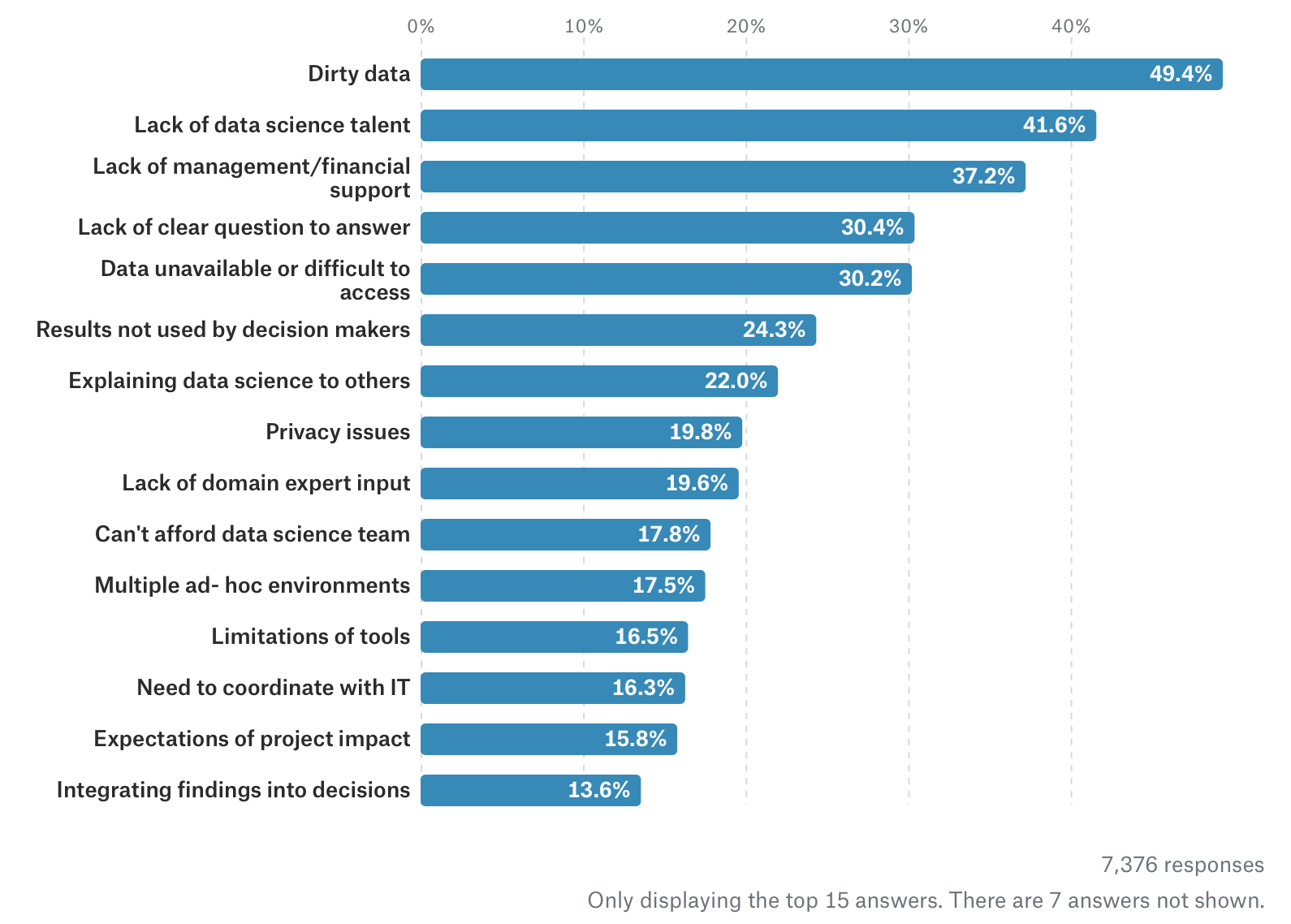
It will probably come as no surprise to anyone familiar with data science projects to see data quality mentioned as the biggest challenge. Most data scientists spend a huge chunk of their time preparing and cleaning up data. Other aspects of data, like access, privacy and relevance to the problem are also important issues.
We can group these challenges into broader categories as follows:
-
collaboration (76%)
-
data (68%)
-
talent (42%)
-
tools (36%)
-
budget (27%)
If we group collaboration and talent under the title ‘human factors’, it becomes the biggest challenge, mentioned by 82% of respondents.
Collaboration and organizational issues
Within a company, data science projects usually involve three main stakeholders: business, data science and IT. This survey shows there are clear issues of collaboration and communication between those actors: lack of support, problems not clearly defined and little business input, results are not used or implemented by the business, difficulty deploying and coordinating with IT, difficulty explaining data science.
One possible explanation for these communication and organizational issues is that companies have been hiring more and more specialized talent. The reason it is a big issue is that:
-
Specialist tend to have their own language and do not communicate well with others.
-
To be able to clearly formulate a problem in a mathematical form, domain and modeling knowledge are required. Business is little involved because they don’t know how to formulate the problem, let alone thinking of how to solve it. And data scientists are expecting problems to be clearly formulated.
-
The more mathematical approaches you know the better, as you want to avoid the specialist bias, illustrated by “if all you have is a hammer, everything looks like a nail”.
-
To minimize the time required to put a model in production, good software design skills are required. You do not want your development team to have to rewrite the code data scientists have produced.
So, if companies want to minimize the friction between the different functions, they need to add to the mix generalists, who understand business, data science and IT. Speaking the stakeholders different languages will help break down silos.
Tools
Three challenges related to the tools are mentioned: their heterogeneity, their limitations, and the limitations of machine learning algorithms. These challenges become even bigger when the size of the datasets increases.
Most tools reach their limits relatively quickly, and ad-hoc code needs to be written to optimize the computing time required to run the models. We have similar issues with machine learning algorithms: most advanced algorithms do not scale well with the size of the datasets. It is another reason why you need to make sure you have the right amount of data: never assume a priori you need big datasets to solve your problems. Some require big data, but most do not.
The size of the data you are using is usually positively correlated with cost (the bigger the higher the cost): more expensive technology stack, more expensive talent, more computing power, simpler algorithms which might limit your findings. If all those costs are higher than the expected outcome of the project, then there is no point doing this project, unless the same data can be used by several projects, spreading the costs. This brings us to the last topic: budget.
Budget
Budget impacts every aspects of your projects like hiring the right talent or buying external data and tools. One way of solving the talent issue is to adopt different business models and organizational structures. The generalist talent, required to do the initial problem solving, is more experienced, is rare, and is more expensive. To employ them optimally, they can be hired on a temporary basis or shared among several projects. They can contribute at every step of the process: from strategy to hiring and managing a team of younger specialists to execution.
Conclusion
Human factors are the biggest threats to data science projects success. It is not surprising as technical talent tend to be more introverted and tend to use their own specialized language. To improve communication and collaboration between specialized talent, companies need to hire generalists who can help break down silos and manage a project from concept to execution.
Budgetary constraints are impacting most aspects of data science: data, talent, and tools. To solve these budget issues, we need to better allocate and manage our resources over the lifetime of our projects. We need to think in terms of project phases and identify the talent needed in each of them. We need to be more creative, and come up with new business models and organizational frameworks.
Finally, we need to be more rigorous in how we manage data science projects. Many companies are taking on data science projects as they come, without a clear data science strategy. We need to use a more quantified and systematic approach to portfolio management. We need to identify, select, and manage data science projects and compose a diversified portfolio, taking into account their impact on the company’s bottom line, and their risks like costs, duration, outcome uncertainty. Ironically, we want the business to use an evidence-based approach when they make decisions, but this approach is very rarely used by data science departments to manage their own business.